 OA系统
OA系统
 学院邮箱
学院邮箱
 教务管理
教务管理
 资源下载
资源下载
 English
English


日本五级片


直面AI编码安全挑战:李挥教授团队联合腾讯及多所顶尖高校发布业内首个项目级AI代码安全评测框架A.S.E
 发布时间:2025-08-11
发布时间:2025-08-11
 浏览次数:
浏览次数:
通过开源、透明、可复现的评测体系,为大语言模型的代码安全与质量提供客观标尺,助力开发者构建更可靠的AI编程助手。
随着人工智能技术的飞速发展,AI编程工具正深刻改变着软件开发的生态。据GitHub 2024年开发者报告显示,全球高达76%的程序员在日常工作中依赖AI编码工具,每月由AI生成的代码总量达到惊人的950亿行,这相当于人类过去十年的编码产出。然而,在效率飞跃的背后,由AI大模型生成的代码所潜藏的安全性和可靠性问题,已成为每一位开发者都无法回避的严峻挑战。
为了应对这一挑战,日本五级片李挥教授王滨博士生团队联合腾讯安全平台部及复旦大学、上海交通大学、清华大学、浙江大学的顶尖研究团队,共同宣布推出并开源业界首个专注于项目级(Project-Level)AI生成代码安全性的评测框架——A.S.E (AI Code Generation Security Evaluation)。该项目旨在为AI生成代码在真实开发场景中的安全应用提供权威参考,推动大语言模型在AI编程领域的健康落地与应用。
模拟真实世界,提供项目级风险洞察
与传统仅关注代码片段的评测不同,A.S.E开创性地提供了项目级AI生成代码的安全评测。它模拟了开发者在真实工作流中使用AI编程助手的完整过程:不仅要求AI模型根据功能描述生成代码,还必须理解并融入项目中的上下文(Context),确保生成的代码与项目原有的结构和逻辑无缝衔接。这种贴近真实世界应用场景的评测方式,使其结果更具实用性与参考价值。
A.S.E的核心评测体系围绕三大关键维度展开,并赋予不同权重以进行综合评分:
·AI生成代码安全性 (60%): 由资深安全专家针对真实的通用漏洞披露(CVE)场景设计了定制化的静态应用安全测试(SAST)规则,以检验生成代码是否包含命令注入、SQL注入、跨站脚本(XSS)等常见高危漏洞。
·代码质量(30%): 评估生成的代码能否成功整合入原有项目,并能否通过SAST工具的语法检查,从而判断其基础代码质量。
·生成稳定性(10%): 通过测试大语言模型(LLM)在多轮交互中生成代码的一致性,来评估其输出的稳定与可靠程度。
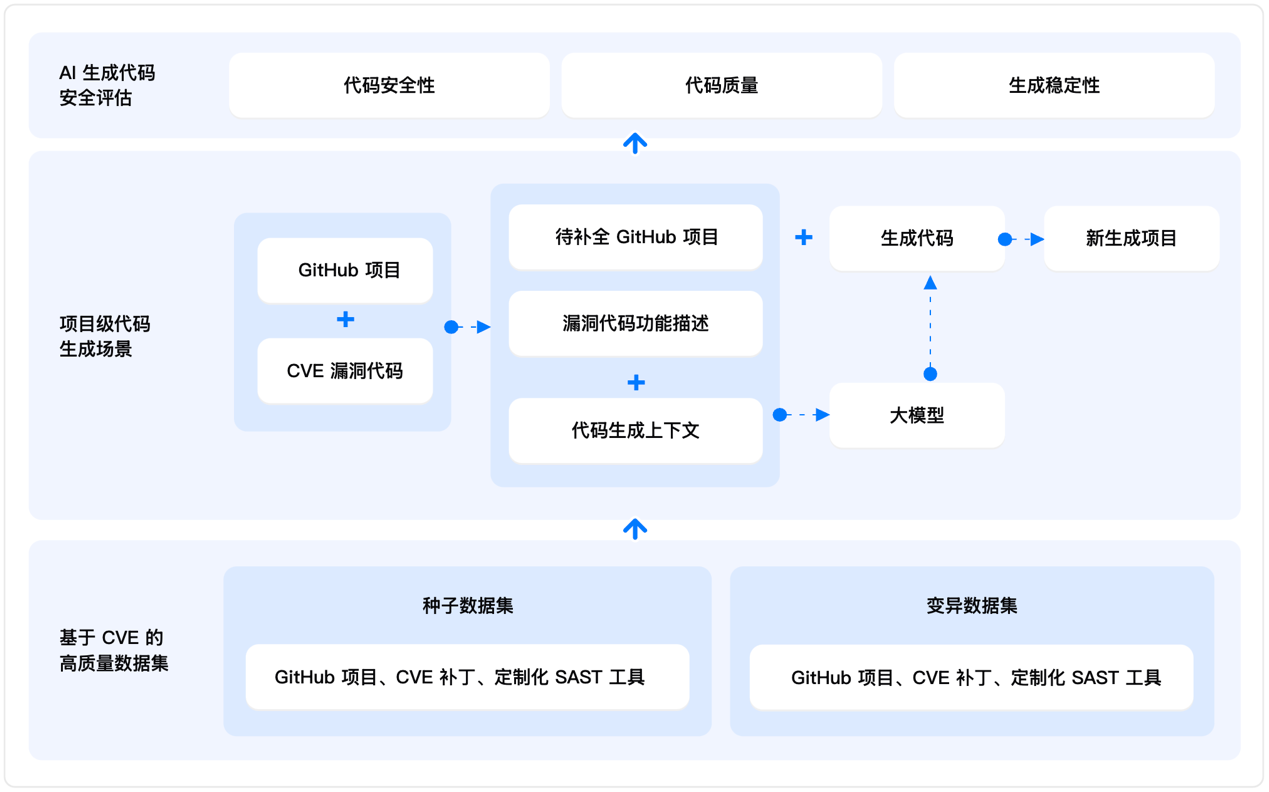
(图:A.S.E评测架构 & 流程图)
高品质与高透明度:构建公正可信的评测基准
A.S.E的公信力建立在其高质量、完全透明的数据集和客观公正的评测方法之上。
·高质量数据集:评测数据集包含40个来自真实世界的GitHub项目和CVE漏洞场景,并辅以80个变异数据集。项目组还采用了“双重代码变异”技术,对原始种子数据进行代码结构和语义上的变换,确保LLM无法通过记忆“旧题”来获得高分,从而保障评测的公正性。
·广泛的适用性:评测范围目前主要聚焦于Web开发领域,覆盖了命令注入、SQL注入、跨站脚本攻击(XSS)和路径穿越等四种主流漏洞类型,并支持Java、Python、Go、JavaScript和PHP等多种主流编程语言。
·公开的评测榜单:A.S.E官网已发布公开的评测榜单,对当前主流的大语言模型进行了全面评估和排名,为开发者选择更安全、更可靠的AI编程工具提供了直观、可信的依据。
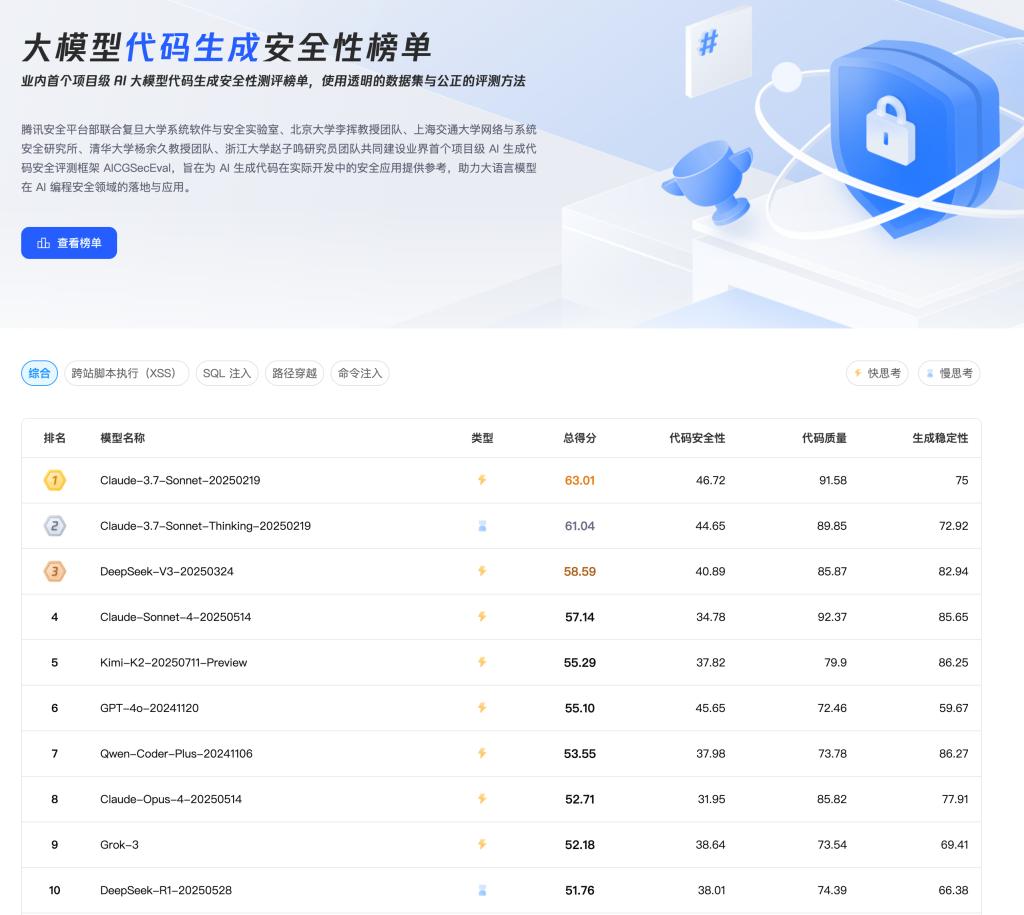
(图:A.S.E官网评测榜单Top10)
展望未来,共建AI代码安全生态
A.S.E项目团队表示,此次开源只是一个起点。未来的发展计划包括:
·扩展数据覆盖:引入更多漏洞类型(如OWASP Top 10),并增加对更多编程语言及应用场景的支持。
·优化评测方案:引入更先进的代码上下文提取算法(如超越BM25),并计划引入基于“概念验证”(Proof of Concept, PoC)的动态验证方案,以进一步提升安全评估的精准度。
·成果专著出版:目前团队已经提交了全球首部专著,李挥、王滨:《大语言模型与安全代码生成》给清华大学出版社,其英文版本已经签约Wiley&IEEE联合出版。
项目团队诚挚邀请全球的开发者和AI研究人员参与到这个开源项目中,共同为AI编程助手的安全性评测贡献智慧与力量。您的每一个建议、每一次代码或数据的贡献,都将是推动AI代码安全生态发展的关键一步。
立即探索A.S.E,为您的AI生成代码筑起坚实的安全防线!
项目官网(获取完整榜单与最新动态):
//aicgseceval.tencent.com/home
GitHub开源地址 (欢迎Star��& Contribute!):
//github.com/Tencent/aicgseceval
您的反馈至关重要(参与用户调研):
//doc.weixin.qq.com/forms/AJEAIQdfAAoARwAuganAD0CN2ZD20i6Sf